Knowledge Base
Summary
How do I reuse an existing PV - after re-creating Kubernetes StatefulSet and its PVC
How to install OpenEBS in OpenShift 4.x?
How to enable Admission-Controller in OpenShift environment?
How to setup default PodSecurityPolicy to allow the OpenEBS pods to work with all permissions?
How to prevent container logs from exhausting disk space?
How to create a BlockDeviceClaim for a particular BlockDevice?
How to provision Local PV on K3OS?
How to make cStor volume online if 2 replicas of 3 are lost?
How to reconstruct data from healthy replica to replaced one?
How to verify whether cStor volume is running fine?
Expanding Jiva Storage Volumes
How do I reuse an existing PV - after re-creating Kubernetes StatefulSet and its PVC
There are some cases where it had to delete the StatefulSet and re-install a new StatefulSet. In the process you may have to delete the PVCs used by the StatefulSet and retain PV policy by ensuring the Retain as the "Reclaim Policy". In this case, following are the procedures for re-using an existing PV in your StatefulSet application.
-
Get the PV name by following command and use it in Step 2.
kubectl get pvFollowing is an example output
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGEpvc-cc6767b4-52e8-11e9-b1ef-42010a800fe7 5G RWO Delete Bound default/mongo-persistent-storage-mongo-0 mongo-pv-az 9m -
Patch corresponding PV's reclaim policy from "Delete" to "Retain". So that PV will retain even its PVC is deleted.This can be done by using the steps mentioned here.
Example Output:
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGEpvc-cc6767b4-52e8-11e9-b1ef-42010a800fe7 5G RWO Retain Bound default/mongo-persistent-storage-mongo-0 mongo-pv-az 9m -
Get the PVC name by following command and note down the PVC name. You have to use this same PVC name while creating new PVC.
kubectl get pvcExample Output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEmongo-persistent-storage-mongo-0 Lost pvc-cc6767b4-52e8-11e9-b1ef-42010a800fe7 0 mongo-pv-az 4s -
Delete StatefulSet application and associated PVCs.
-
Create a new PVC YAML named newPVC.yaml with same configuration. Specify old PV name belongs to volumeName under the PVC spec.
apiVersion: v1kind: PersistentVolumeClaimmetadata:annotations:pv.kubernetes.io/bind-completed: "yes"pv.kubernetes.io/bound-by-controller: "yes"volume.beta.kubernetes.io/storage-provisioner: openebs.io/provisioner-iscsilabels:environment: testopenebs.io/replica-anti-affinity: vehicle-dbrole: mongoname: mongo-persistent-storage-mongo-0namespace: defaultspec:accessModes:- ReadWriteOnceresources:requests:storage: 5GstorageClassName: mongo-pv-azvolumeName: pvc-cc6767b4-52e8-11e9-b1ef-42010a800fe7status:accessModes:- ReadWriteOncecapacity:storage: 5G -
Apply the modified PVC YAML using the following command
kubectl apply -f newPVC.yamlExample Output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEmongo-persistent-storage-mongo-0 Lost pvc-cc6767b4-52e8-11e9-b1ef-42010a800fe7 0 mongo-pv-az 4s -
Get the newly created PVC UID using
kubectl get pvc mongo-persistent-storage-mongo-0 -o yaml. -
Update the uid under the claimRef in the PV using the following command. The PVC will get attached to the PV after editing the PV with correct uid.
kubectl edit pv pvc-cc6767b4-52e8-11e9-b1ef-42010a800fe7 -
Get the updated PVC status using the following command.
kubectl get pvcExample Output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEmongo-persistent-storage-mongo-0 Bound pvc-cc6767b4-52e8-11e9-b1ef-42010a800fe7 5G RWO mongo-pv-az 5m -
Apply the same StatefulSet application YAML. The pod will come back online by re-using the existing PVC. The application pod status can be get by following command.
kubectl get pods -n <namespace>
How to scale up Jiva replica?
From 0.9.0 OpenEBS version, Jiva pod deployment are scheduling with nodeAffinity. For scaling up Jiva replica count, the following steps has to be performed.
-
Get the deployment details of replica of corresponding Jiva volume using the following command. If it is deployed in
openebsnamespace, use corresponding namespace appropriately in the following commands.kubectl get deployFollowing is an example output.
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGEpercona 1 1 1 1 54spvc-4cfacfdd-76d7-11e9-9319-42010a800230-ctrl 1 1 1 1 53spvc-4cfacfdd-76d7-11e9-9319-42010a800230-rep 1 1 1 1 53s -
Edit the corresponding replica deployment of the Jiva volume using the following command.
kubectl edit deploy <replica_deployment_of_corresponding_volume>Example:
kubectl edit deploy pvc-4cfacfdd-76d7-11e9-9319-42010a800230-repPerform Step 3 and 4 and then save the changes. It is required to modify the fields of replica count and hostname details where the replica pods has to be scheduled.
-
Edit
replicasvalue underspecwith the required number. In this example, it wasreplicas: 1during the initial deployment. With following change, replicas count will change to 2.Example:
replicas: 2 -
Add corresponding hostnames under value in
spec.template.spec.affinity.nodeAffinity.nodeSelectorTerms.key.values. The following is the sample snippet for adding the required hostnames. In the following snippet, it is added the hostname of second node in the mentioned path.spec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- gke-md-jiva-default-pool-15a2475b-bxr5- gke-md-jiva-default-pool-15a2475b-gzx3 -
After modifying the above changes, save the configuration. With this change , new replica pods will be running and following command will get the details of replica pods.
kubectl get pod -o wideThe following is an example output.
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODEpercona-66b4fd4ddf-xvswn 1/1 Running 0 32mpvc-4cfacfdd-76d7-11e9-9319-42010a800230-ctrl-68d94478df-drj6r 2/2 Running 0 32mpvc-4cfacfdd-76d7-11e9-9319-42010a800230-rep-f9ff69c6-6lcfz 1/1 Running 0 25spvc-4cfacfdd-76d7-11e9-9319-42010a800230-rep-f9ff69c6-9jbfm 1/1 Running 0 25s
How to install OpenEBS in OpenShift 4.x
Tested versions
OpenEBS has been tested in the following configurations;
| OpenShift Version | OS | Status |
|---|---|---|
| 4.2 | RHEL7.6, CoreOS 4.2 | Tested |
| 3.10 | RHEL7.6, CoreOS 4.2 | Tested |
Notes on security
Note: Earlier documentation for installing OpenEBS on OpenShift required disabling SELinux. This is no longer necessary - SELinux does not need to be disabled now.
Note: However, the OpenEBS operator, and some projects that use OpenEBS volumes do require privileged Security Context Constraints. This is described below.
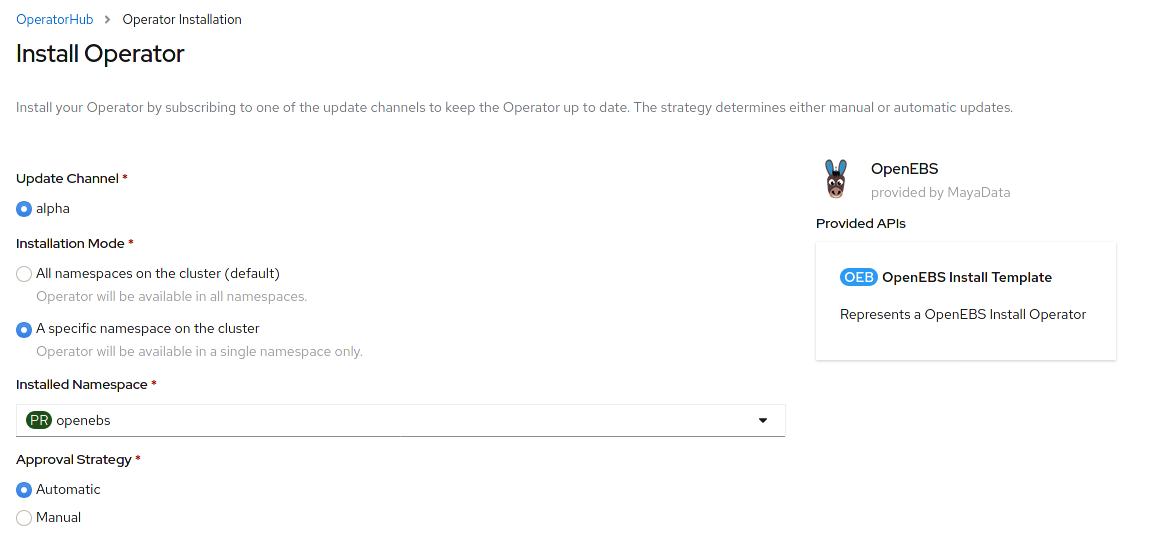
Installation option: via the OperatorHub
The easiest way to install OpenEBS is by using the operator in the OperatorHub;
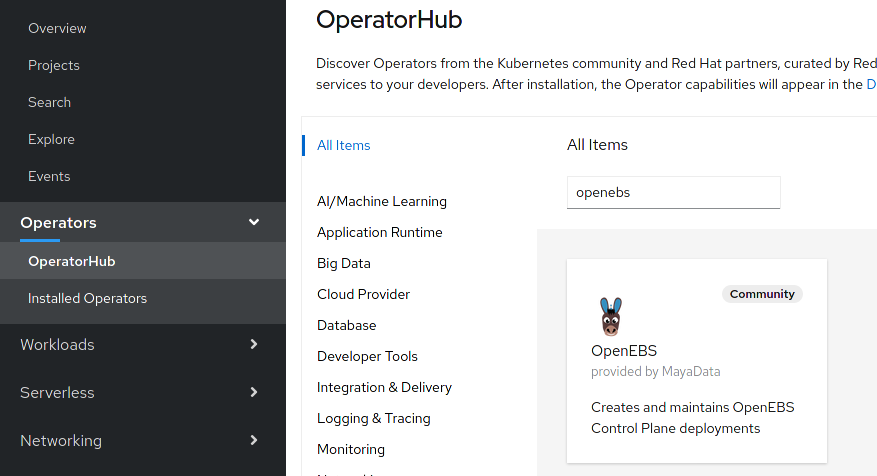
This guide recommends installing the operator into an empty openebs
namespace.
Installation option: via "manual" install
-
Find the latest OpenEBS release version from here and download the latest OpenEBS operator YAML in your master node. The latest openebs-operator YAML file can be downloaded using the following way.
wget https://openebs.github.io/charts/openebs-operator-1.2.0.yaml -
Apply the modified the YAML using the following command.
kubectl apply -f openebs-operator-1.2.0.yaml
Adding privileged SCC to the openebs-maya-operator service account
The examples below assume you have installed OpenEBS in the OpenEBS project.
If you have used another namespace, change -n accordingly.
Add the privileged SecurityContextConstraint (SCC) to the OpenEBS service account;
oc adm policy add-scc-to-user privileged -z openebs-maya-operator -n openebs
Example output:
securitycontextconstraints.security.openshift.io/privileged added to: ["system:serviceaccount:openebs:openebs-maya-operator"]
Quickly verifying the installation
Verify OpenEBS pod status by using kubectl get pods -n openebs, all pods
should be "Running" after a few minutes. If pods are not running after a few
minutes, start debugging with oc get events and viewing these container logs.
NAME READY STATUS RESTARTS AGE
maya-apiserver-594699887-4x6bj 1/1 Running 0 60m
openebs-admission-server-544d8fb47b-lxd52 1/1 Running 0 60m
openebs-localpv-provisioner-59f96b699-dpf8l 1/1 Running 0 60m
openebs-ndm-4v6kj 1/1 Running 0 60m
openebs-ndm-8g226 1/1 Running 0 60m
openebs-ndm-kkpk7 1/1 Running 0 60m
openebs-ndm-operator-74d9c78cdc-lbtqt 1/1 Running 0 60m
openebs-provisioner-5dfd95987b-nhwb9 1/1 Running 0 60m
openebs-snapshot-operator-5d58bd848b-94nnt 2/2 Running 0 60m
If you are seeing errors with hostNetwork or similar, this is likely because
the serviceAccount for that container has not been added to the privileged SCC.
Next Steps:
- You may want to fully verifying the OpenEBS installation in more detail.
- After verification, you probably want to select a CAS Engine.
Adding privileged SCC to projects that use OpenEBS volumes
When you create a PVC using a StorageClass for OpenEBS, a ctrl and rep
deployment will be created for that PVC. The rep containers also need to be
privileged.
Switch to a project that is using OpenEVS PVs;
oc project myproject
To stop the whole project running as privileged, you could create a new serviceAccount for the project, and only run the Deployment/pvc-...-rep using that service account.
However, an easy (and lazy, insecure) workaround is change this project's
default ServiceAccount to be privileged.
oc adm policy add-scc-to-user privileged -z default -n myproject
Note: OpenShift automatically creates a project for every namespace, and a default ServiceAccount for every project.
Once these permissions have been granted, you can provision persistent volumes using OpenEBS. See CAS Engines for more details.
How to enable Admission-Controller in OpenShift 3.10 and above
The following procedure will help to enable admission-controller in OpenShift 3.10 and above.
-
Update the
/etc/origin/master/master-config.yamlfile with below configuration.admissionConfig:pluginConfig:ValidatingAdmissionWebhook:configuration:kind: DefaultAdmissionConfigapiVersion: v1disable: falseMutatingAdmissionWebhook:configuration:kind: DefaultAdmissionConfigapiVersion: v1disable: false -
Restart the API and controller services using the following commands.
# master-restart api# master-restart controllers
How to setup default PodSecurityPolicy to allow the OpenEBS pods to work with all permissions?
Apply the following YAML in your cluster.
-
Create a Privileged PSP
apiVersion: extensions/v1beta1kind: PodSecurityPolicymetadata:name: privilegedannotations:seccomp.security.alpha.kubernetes.io/allowedProfileNames: '*'spec:privileged: trueallowPrivilegeEscalation: trueallowedCapabilities:- '*'volumes:- '*'hostNetwork: truehostPorts:- min: 0max: 65535hostIPC: truehostPID: truerunAsUser:rule: 'RunAsAny'seLinux:rule: 'RunAsAny'supplementalGroups:rule: 'RunAsAny'fsGroup:rule: 'RunAsAny' -
Associate the above PSP to a ClusterRole
kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata:name: privilegedpsprules:- apiGroups: ['extensions']resources: ['podsecuritypolicies']verbs: ['use']resourceNames:- privileged -
Associate the above Privileged ClusterRole to OpenEBS Service Account
apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:annotations:rbac.authorization.kubernetes.io/autoupdate: "true"name: openebspsproleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: privilegedpspsubjects:- kind: ServiceAccountname: openebs-maya-operatornamespace: openebs -
Proceed to install the OpenEBS. Note that the namespace and service account name used by the OpenEBS should match what is provided in the above ClusterRoleBinding.
How to prevent container logs from exhausting disk space?
Container logs, if left unchecked, can eat into the underlying disk space causing disk-pressure conditions
leading to eviction of pods running on a given node. This can be prevented by performing log-rotation
based on file-size while specifying retention count. One recommended way to do this is by configuring the
docker logging driver on the individual cluster nodes. Follow the steps below to enable log-rotation.
-
Configure the docker configuration file /etc/docker/daemon.json (create one if not already found) with the log-options similar to ones shown below (with desired driver, size at which logs are rotated, maximum logfile retention count & compression respectively):
{"log-driver": "json-file","log-opts": {"max-size": "400k","max-file": "3","compress": "true"}} -
Restart the docker daemon on the nodes. This may cause a temporary disruption of the running containers & cause the node to show up as
Not Readyuntil the daemon has restarted successfully.systemctl daemon-reloadsystemctl restart docker -
To verify that the newly set log-options have taken effect, the following commands can be used:
-
At a node-level, the docker logging driver in use can be checked via the following command:
docker infoThe
LogConfigsection of the output must show the desired values:"LogConfig": {"Type": "json-file","Config": {}
-
At the individual container level, the log options in use can be checked via the following command:
docker inspect <container-id>The
LogConfigsection of the output must show the desired values:"LogConfig": {"Type": "json-file","Config": {"max-file": "3","max-size": "400k","compress": "true"}}
-
-
To view the current & compressed files, check the contents of the
/var/lib/docker/containers/<container-id>/directory. The symlinks at/var/log/containers/<container-name>refer to the above.
NOTES:
-
The steps are common for Linux distributions (tested on CentOS, RHEL, Ubuntu)
-
Log rotation via the specified procedure is supported by docker logging driver types:
json-file (default), local -
Ensure there are no dockerd cli flags specifying the
--log-opts(verify viaps -auxor service definition files in/etc/init.dor/etc/systemd/system/docker.service.d). The docker daemon fails to start if an option is duplicated between the file and the flags, regardless their value. -
These log-options are applicable only to the containers created after the dockerd restart (which is automatically taken care by the kubelet)
-
The
kubectl logreads the uncompressed files/symlinks at/var/log/containersand thereby show rotated/rolled-over logs. If you would like to read the retained/compressed log content as well usedocker logcommand on the nodes. Note that reading from compressed logs can cause temporary increase in CPU utilization (on account of decompression actions performed internally) -
The log-opt
compress: true:is supported from Docker version: 18.04.0. Themax-file&max-sizeopts are supported on earlier releases as well.
How to create a BlockDeviceClaim for a particular BlockDevice?
There are certain use cases where the user does not need some of the BlockDevices discovered by OpenEBS to be used by any of the storage engines (cStor, LocalPV, etc.). In such scenarios, users can manually create a BlockDeviceClaim to claim that particular BlockDevice, so that it won't be used by cStor or Local PV. The following steps can be used to claim a particular BlockDevice:
-
Download the BDC CR YAML from
node-disk-managerrepository.wget https://raw.githubusercontent.com/openebs/node-disk-manager/master/deploy/crds/openebs_v1alpha1_blockdeviceclaim_cr.yaml -
Provide the BD name of the corresponding BlockDevice which can be obtained by running
kubectl get bd -n <openebs_installed_namespace> -
Apply the modified YAML spec using the following command:
kubectl apply -f openebs_v1alpha1_blockdeviceclaim_cr.yaml -n <openebs_installed_namespace>Note: The blockdeviceclaim CR should be created on the same namespace where openebs is installed.
-
Verify if particular BDC is created for the given BD cr using the following command:
kubectl get bdc -n <openebs_installed_namespace>
How to provision Local PV on K3OS?
K3OS can be installed on any hypervisor The procedure for deploying K3OS on VMware environment is provided in the following section. There are 3 steps for provisioning OpenEBS Local PV on K3OS.
- Configure server(master)
- Configure agent(worker)
- Deploying OpenEBS
The detailed information of each steps are provided below.
-
Configure server(master)
-
Download the ISO file from the latest release and create a virtual machine in VMware. Mount the ISO file into hypervisor and start a virtual machine.
-
Select Run k3OS LiveCD or Installation and press
<ENTER>. -
The system will boot-up and gives you the login prompt.
-
Login as rancher user without providing password.
-
Set a password for rancher user to enable connectivity from other machines by running
sudo passwd rancher. -
Now, install K3OS into disk. This can be done by running the command
sudo os-config. -
Choose the option 1.Install to disk . Answer the proceeding questions and provide rancher user password.
-
As part of above command execution, you can configure the host as either server or agent. Select
1.serverto configure K3s master. -
While configuring server, set cluster secret which would be used while joining nodes to the server. After successful installation and server reboot, check the cluster status.
-
Run following command to get the details of nodes:
kubectl get nodesExample output:
NAME STATUS ROLES AGE VERSIONk3os-14539 Ready <none> 2m33s v1.14.1-k3s.4
-
-
Configure agent(worker)
-
Follow the above steps till installing K3OS into disk in all the hosts that you want to be part of K3s cluster.
-
To configure kubernetes agent with K3OS, select the option
2. agentwhile runningsudo os-configcommand. You need to provide URL of server and secret configured during server configuration. -
After performing this, Kubernetes agent will be configured as follows and it will be added to the server.
-
Check the cluster configuration by checking the nodes using the following command:
Kubectl get nodesExample output:
NAME STATUS ROLES AGE VERSIONk3os-14539 Ready <none> 5m16s v1.14.1-k3s.4k3os-32750 Ready <none> 49m v1.14.1-k3s.4
-
-
Installing OpenEBS
-
Run the following command to install OpenEBS from master console:
kubectl apply -f https://openebs.github.io/charts/openebs-operator-1.1.0.yaml -
Check the OpenEBS components by running the following command:
NAME READY STATUS RESTARTS AGEmaya-apiserver-78c966c446-zpvhh 1/1 Running 2 101sopenebs-admission-server-66f46564f5-8sz8c 1/1 Running 0 101sopenebs-localpv-provisioner-698496cf9b-wkf95 1/1 Running 0 101sopenebs-ndm-9kt4n 0/1 ContainerCreating 0 101sopenebs-ndm-mxqcf 0/1 ContainerCreating 0 101sopenebs-ndm-operator-7fb4894546-d2whz 1/1 Running 1 101sopenebs-provisioner-7f9c99cf9-9jlgc 1/1 Running 0 101sopenebs-snapshot-operator-79f7d56c7d-tk24k 2/2 Running 0 101sNote that
openebs-ndmpods are in not created successfully. This is due to the lack of udev support in K3OS. More details can be found here. -
Now user can install Local PV on this cluster. Check the StorageClasses created as part of OpenEBS deployment by running the following command.
kubectl get scExample output:
NAME PROVISIONER AGEopenebs-device openebs.io/local 57mopenebs-hostpath openebs.io/local 57mopenebs-jiva-default openebs.io/provisioner-iscsi 57mopenebs-snapshot-promoter volumesnapshot.external-storage.k8s.io/snapshot-promoter 57m -
The default StorageClass
openebs-hostpathcan be used to create local PV on the path/var/openebs/localin your Kubernetes node. You can either useopenebs-hostpathstorage class to create volumes or create new storage class by following the steps mentioned here.Note: OpenEBS local PV will not be bound until the application pod is scheduled as its volumeBindingMode is set to WaitForFirstConsumer. Once the application pod is scheduled on a certain node, OpenEBS Local PV will be bound on that node.
-
How to make cStor volume online if 2 replicas of 3 are lost?
Application that is using cStor volume can run IOs, if at least 2 out of 3 replicas (i.e., > 50% of ReplicationFactor) have data with them. If 2 out of 3 replicas lost data, cStor volume goes into RO (read-only) mode, and, application can get into crashed state. This section is to provide the steps to bring back volume online by scaling down replicas to 1 with a consideration of ReplicationFactor as 3 in the examples.
Perform the following steps to make the cStor volume online:
- Check the current state of CVRs of a cStor volume.
- Scaling down the replica count to 1 from 3.
- Make the volume mount point into RW mode from the Worker node where application is scheduled.
The detailed information of each steps are provided below.
-
Check the current state of CVRs of a cStor volume
-
Run the following command to get the current state of CVR of a cStor volume.
kubectl get cvr -n openebsOutput will be similar to the following:
NAME USED ALLOCATED STATUS AGEpvc-5c52d001-..........-cstor-sparse-pool-1irk 7.07M 4.12M Degraded 12mpvc-5c52d001-..........-cstor-sparse-pool-a1ud 6K 6K Degraded 12mpvc-5c52d001-..........-cstor-sparse-pool-sb1v 8.15M 4.12M Healthy 12m -
Check the details of the corresponding cStor volume using the following command:
kubectl get cstorvolume <cStor_volume_name> -n openebs -o yamlThe following is a snippet of the output of the above command:
apiVersion: v1items:- apiVersion: openebs.io/v1alpha1kind: CStorVolumemetadata:…..name: pvc-5c52d001-c6a1-11e9-be30-42010a800094namespace: openebsuid: 5c767ae5-c6a1-11e9-be30-42010a800094spec:…..iqn: iqn.2016-09.com.openebs.cstor:pvc-5c52d001-c6a1-11e9-be30-42010a800094targetPortal: 10.108.4.158:3260status:......**phase: Offline**replicaStatuses:- checkpointedIOSeq: "0"......mode: **Healthy**quorum: **"1"**replicaId: "10135959964398189975"- checkpointedIOSeq: "0"......mode: **Degraded**quorum: **"0"**replicaId: "9431770906853612612"- checkpointedIOSeq: "0"......mode: **Degraded**quorum: **"0"**replicaId: "3920180363968537568"In the above snippet, quorum value of one replica is in
ONand quorum value of other two areOFFmode and cStor volume is inOfflinestate. Running IOs now on this cStor volume will get IO error on Node as below:/ # touch /mnt/store1/file2touch: /mnt/store1/file2: Input/output error
-
-
Scaling down the replica count to 1 from 3.
At this point, user can make the target pod healthy with the single replica which is in quorum.
Note: Target pod is made healthy on the assumption that the replica which is in quorum have the latest data with it. In other words, only the data that is available with the replica which is in quorum will be served.
The following steps will help to make the target pod healthy with a single replica which is in quorum.
-
Edit CStorVolume CR to set ReplicationFactor and ConsistencyFactor to 1.
-
Check the details of the corresponding cStor volume using the following command:
kubectl get cstorvolume <cStor_volume_name> -n openebs -o yamlThe following is a snippet of the output of the above command:
apiVersion: v1items:- apiVersion: openebs.io/v1alpha1kind: CStorVolumemetadata:…..name: pvc-5c52d001-c6a1-11e9-be30-42010a800094namespace: openebsuid: 5c767ae5-c6a1-11e9-be30-42010a800094spec:…..replicationFactor: 1consistencyFactor: 1iqn: iqn.2016-09.com.openebs.cstor:pvc-5c52d001-c6a1-11e9-be30-42010a800094targetPortal: 10.108.4.158:3260status:......**phase: Healthy**replicaStatuses:- checkpointedIOSeq: "0"......mode: **Healthy**quorum: **"1"**replicaId: **"10135959964398189975"**
-
-
Restart target pod by running following command
kubectl delete pod -n openebs <target pod name>
Now the cStor volume will be running with a single replica.
-
-
Make the volume mount point into RW mode from the Worker node where application is scheduled.
Next, user should make the volume mount point into RW mode using the following steps.
-
If mount point of the volume went to RO, restart the application pod to bring back the mount point to RW state.
-
If application still remains in
CrashLoopbackstate due to RO mode of mount point (kubectl describeof application pod will show the reason), follow below steps to convert it into RW:-
Login to node where application pod is running.
Get the node details where the application pod is running using the following command.
Kubectl get pod -n <namespace> -o wideAfter identifying the node, ssh into the node.
-
Find the iSCSI disk related to this PVC.
Run following command inside the node to get the iSCSI disk related to the PVC.
sudo iscsiadm -m session -P 3The output will be similar to the following:
iSCSI Transport Class version 2.0-870version 2.0-874**Target: iqn.2016-09.com.openebs.cstor:pvc-5c52d001-c6a1-11e9-be30-42010a800094** (non-flash)**Current Portal: 10.108.4.158:3260,1**……************************Attached SCSI devices:************************Host Number: 1 State: runningscsi1 Channel 00 Id 0 Lun: 0**Attached scsi disk sdb State: running**From the above output, user can obtain the iSCSI disk related to this PV. In this example, SCSI disk related to this PV is
sdb. -
Unmount the mount points related to this PVC that are in RO.
Next, perform unmount operation on mount points that are related to sdb. The following output will help to get the mount details related to disk sdb:
sudo mount | grep sdbThe output will be similar to the following:
**/dev/sdb** on /var/lib/kubelet/plugins/kubernetes.io/iscsi/iface-default/10.108.4.158:3260-iqn.2016-09.com.openebs.cstor:pvc-5c52d001-c6a1-11e9-be30-42010a800094-lun-0 type ext4**/dev/sdb** on /home/kubernetes/containerized_mounter/rootfs/var/lib/kubelet/plugins/kubernetes.io/iscsi/iface-default/10.108.4.158:3260-iqn.2016-09.com.openebs.cstor:pvc-5c52d001-c6a1-11e9-be30-42010a800094-lun-0 type ext4 (ro,relatime,stripe=256,data=ordered)**/dev/sdb** on /var/lib/kubelet/pods/5cb0af5a-c6a1-11e9-be30-42010a800094/volumes/kubernetes.io~iscsi/pvc-5c52d001-c6a1-11e9-be30-42010a800094 type ext4 (ro,relatime,stripe=256,data=ordered)**/dev/sdb** on /home/kubernetes/containerized_mounter/rootfs/var/lib/kubelet/pods/5cb0af5a-c6a1-11e9-be30-42010a800094/volumes/kubernetes.io~iscsi/pvc-5c52d001-c6a1-11e9-be30-42010a800094 type ext4 (ro,relatime,stripe=256,data=ordered)Perform unmount on the above found mountpoints.
-
Perform
iscsiadm logoutandiscsiadm loginof the iSCSI session related to this PVC.From the node related to application pod, perform below command to logout:
sudo iscsiadm -m node -t iqn.2016-09.com.openebs.cstor:pvc-5c52d001-c6a1-11e9-be30-42010a800094 -p 10.108.4.158:3260 -uFrom the node related to application pod, perform below command to login:
sudo iscsiadm -m node -t iqn.2016-09.com.openebs.cstor:pvc-5c52d001-c6a1-11e9-be30-42010a800094 -p 10.108.4.158:3260 -l -
Find the new iSCSI disk related to this PVC.
Get the new iSCSI disk name after login using the following command:
sudo iscsiadm -m session -P 3Output will be similar to the following:
iSCSI Transport Class version 2.0-870version 2.0-874**Target: iqn.2016-09.com.openebs.cstor:pvc-5c52d001-c6a1-11e9-be30-42010a800094** (non-flash)……..************************Attached SCSI devices:************************Host Number: 1 State: runningscsi1 Channel 00 Id 0 Lun: 0**Attached scsi disk sdc State: running** -
Mount the mount points that are unmounted in 3rd step .
Perform mount of the SCSI disk on the mount points which are unmounted in 3rd step. The application may still remain in RO state. If so, restart the application pod.
-
-
How to reconstruct data from healthy replica to replaced ones?
Consider the case where cStorVolumes have replication enabled, and one/few of its replicas got replaced, i.e., they are new and lost the data. In this case, cStor volume will be in Offline state and unable to recover data to the replaced replicas from healthy replica automatically.
Reconstructing data from healthy replica to the replaced ones can be done using the following steps. To perform the following steps, cStor volume should be in Online. If cStor volume is not in Online, make it online using the steps mentioned here.
Run the following command to get the current state of CVR of a cStor volume.
kubectl get cvr -n openebs
Output will be similar to the following:
NAME USED ALLOCATED STATUS AGE
pvc-5c52d001-..........-cstor-sparse-pool-1irk 7.07M 4.12M Degraded 12m
pvc-5c52d001-..........-cstor-sparse-pool-a1ud 6K 6K Degraded 12m
pvc-5c52d001-..........-cstor-sparse-pool-sb1v 8.15M 4.12M Healthy 12m
For easy representation, healthy replica will be referred to as R1, and offline replica that needs to be reconstructed with data will be referred to as R2. User should keep the information of healthy replica and replaced replica and associated pool in handy.
In this example, R1 is pvc-5c52d001-c6a1-11e9-be30-42010a800094-cstor-sparse-pool-sb1v and R2 is pvc-5c52d001-c6a1-11e9-be30-42010a800094-cstor-sparse-pool-a1ud . Pool name associated to R1 is cstor-sparse-pool-sb1v-77658f4c85-jcgwc and pool name related to R2 is cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md. Pool name can be found by doing zpool list in the pool pod of that particular node.
The following are the steps to reconstruct data from healthy replica to a replaced replica:
- Take base snapshot on R1.
- Copy the base snapshot to R2’s node.
- Apply the base snapshot to the pool of R2.
- Take incremental snapshot on R1.
- Copy the incremental snapshot to R2’s node.
- Apply the above incremental snapshot to the pool of R2.
- Repeat steps 4, 5 and 6 till incremental snapshot is of lesser size.
- Scale down spec.replicas to 0 of client application so that final changes can be transferred.
- Scale down spec.replicas of target pod deployment to 0.
- Perform steps 4, 5 and 6.
- Set TargetIP and Quorum properties on R2.
- Edit cStorVolume CR of this PVC to increase
ReplicationFactorby 1 and to setConsistencyFactorto (ReplicationFactor/2 + 1). - Scale up
spec.replicasto 1 of target pod deployment. - Scale up
spec.replicasof client application - Edit cStorVolume CR of this PVC to increase
ReplicationFactorby 1 and to setConsistencyFactorto (ReplicationFactor/2 + 1). - Restart the cStor target pod deployment.
Step1: Take base snapshot on R1.
-
Exec into cstor-pool-mgt container of pool pod of R1 to run snapshot command:
kubectl exec -it -n openebs -c cstor-pool-mgmt <pool pod name> -- bash -
Run the following command inside the pool pod container to take the base snapshot
zfs snapshot <pool_name>/<PV name>@<base_snap_name>Example command:
root@cstor-sparse-pool-sb1v-77658f4c85-jcgwc:/# zfs snapshot cstor-231fca0f-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094@snap_data1
Step2: Copy the base snapshot to R2’s node.
There are multiple ways to do this. In this article, above created snapshot is streamed to a file. This streamed file is copied to node related to R2. As /tmp directory of the pool pod is mounted on the host node at /var/openebs/sparse/shared-<spc name>, streamed file will be created at R1 and copied at R2 to this location.
-
Stream snapshot to a file:
Exec into cstor-pool-mgmt container of pool pod of R1 to run the below command:
zfs send <pool_name>/<PV name>@<base_snap_name> > /tmp/base_snap_fileExample command:
root@cstor-sparse-pool-sb1v-77658f4c85-jcgwc:/# zfs send cstor-231fca0f-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094@snap_data1 > /tmp/pvc-5c52d001-c6a1-11e9-be30-42010a800094_snap_data1 -
Copy the streamed file to local machine:
gcloud compute --project "<project name>" scp --zone "us-central1-a" <user>@gke-test-default-pool-0337597c-3b5d:/var/openebs/sparse/shared-cstor-sparse-pool/pvc-5c52d001-c6a1-11e9-be30-42010a800094_snap_data1 -
Copy the local copy of streamed file to another node:
gcloud beta compute --project "<project name>" scp --zone "us-central1-a" pvc-5c52d001-c6a1-11e9-be30-42010a800094_snap_data1 <user>@gke-test-default-pool-0337597c-vdg1:/var/openebs/sparse/shared-cstor-sparse-pool/
Step3: Apply the base snapshot to the pool of R2
Applying base snapshot to pool related to R2 involves setting a few parameters. Below are the steps:
-
Exec into
cstor-pool-mgmtcontainer of pool pod related to R2.kubectl exec -it -c cstor-pool-mgmt -n <associated_pool_pod> -- bashExample command:
kubectl exec -it -c cstor-pool-mgmt -n openebs cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md -- bash -
Identify the PV related datasets.
zfs list -t allThe output will be similar to the following:
NAME USED AVAIL REFER MOUNTPOINTcstor-2292c294-c6a1-11e9-be30-42010a800094 9.86M 9.62G 512B /cstor-2292c294-c6a1-11e9-be30-42010a800094**cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094** 6K 9.62G 6K -**cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094@rebuild_snap** 0B - 6K -**cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094_rebuild_clone** 0B 9.62G 6K -Look for PV name in the above list output. In this example, datasets that are in bold are related to this PV.
Note: Dataset which is
<pool name>/<PV name>is the main replica. Dataset that ends with@rebuild_snapis the internally created snapshot, and the one that ends with_rebuild_cloneis internally created clone. -
Unset target IP on the main volume.
Run the following command to unset target ip on the main volume:
zfs set io.openebs:targetip= <pool_name>/<PV name>Example command:
root@cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md:/# zfs set io.openebs:targetip= cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094 -
Delete rebuild_snap snapshot.
Note: Below are destructive steps and need to be performed on verifying that they are the correct ones to be deleted.
zfs destroy <pool_name>/<PV name_rebuild_clone>Example command:
root@cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md:/# zfs destroy cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094_rebuild_clone -
Delete internally created clone related to this PV with suffix as _rebuild_clone.
Note: Below are destructive steps and need to be performed on verifying that they are the correct ones to be deleted.
zfs destroy <pool_name>/<PV name>@rebuild_snapExample command:
root@cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md:/# zfs destroy cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094@rebuild_snap -
Apply the streamed file to offline pool:
cat <base snapshot streamed file> | zfs recv -F <pool name>/<PV name>Example command:
root@cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md:/# cat /tmp/pvc-5c52d001-c6a1-11e9-be30-42010a800094_snap_data1 | zfs recv -F cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094Capacity “USED” can be verified by doing
zfs list -t all
Step4: Take incremental snapshot on R1
-
From
cstor-pool-mgmtcontainer of pool pod related to R1, perform following command:zfs snapshot <pool name>/<PV name>@<incr_snap_name>Example command:
root@cstor-sparse-pool-sb1v-77658f4c85-jcgwc:/# zfs snapshot cstor-231fca0f-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094@snap_data1_data2Please note that snapshot name which is
<incr_snap_name>as mentioned above need to be different for each incremental snapshot.
Step5: Copy the data in incremental snapshot to R2’s node
This involves streaming the incremental data to a file, copying it to R2.
-
Stream incremental snapshot to a file:
From cstor-pool-mgmt container of pool pod of R1, run below command:
zfs send -i <pool_name>/<PV_name>@<prev_snap_name> <pool_name>/<PV_name>@<cur_snap_name> > /tmp/<incr_snap_file1>Example command:
root@cstor-sparse-pool-sb1v-77658f4c85-jcgwc:/# zfs send -i cstor-231fca0f-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094@snap_data1 cstor-231fca0f-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094@snap_data1_data2 > /tmp/pvc-5c52d001-c6a1-11e9-be30-42010a800094_snap_data1_data2Copy the streamed file to R2 following the steps similar to copying the streamed file related to base snapshot.
Step6: Apply the above incremental snapshot to pool of R2
-
Exec into
cstor-pool-mgmtcontainer of pool pod of R2 to run:cat /tmp/<incr_snap_file1> | zfs recv <pool name>/<PV name>Example command to apply incremental snapshot:
root@cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md:/# cat /tmp/pvc-5c52d001-c6a1-11e9-be30-42010a800094_snap_data1_data2 | zfs recv cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094zfs list -t allshould show the dataset related to this PVC with increased "USED" space.Example command:
root@cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md:/# zfs list -t allOutput will be similar to the following:
NAME USED AVAIL REFER MOUNTPOINTcstor-2292c294-c6a1-11e9-be30-42010a800094 85.7M 9.54G 512B /cstor-2292c294-c6a1-11e9-be30-42010a800094**cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094** 84.9M 9.54G 84.9M -cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094@snap_data1 41.5K - 4.12M -cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094@snap_data1_data2 0B - 84.9M -
Step7: Repeat steps 4, 5 and 6 till incremental snapshot is of lesser size
Step 8: Scale down spec.replicas to 0 of client application so that final changes can be transferred.
Step 9:Scale down spec.replicas of target pod deployment to 0.
Step 10: Perform steps 4, 5 and 6
Step 11: Set TargetIP and Quorum properties on R2
Once steps 8,9 and 10 are followed, set targetIP and quorum properties of newly reconstructed R2.
-
Set quorum on the newly reconstructed dataset on R2.
In the cstor-pool-mgmt container of pool pod related to R2, perform the following command:
zfs set quorum=on <pool name>/<PV name>Example command:
root@cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md:/# zfs set quorum=on cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094 -
Set
targetIPon the newly rebuilt dataset on R2zfs set io.openebs:targetip=<service IP related to PV’s target pod> <pool name>/<PV name>Example command:
root@cstor-sparse-pool-a1ud-5dd8bb6fb6-f54md:/# zfs set io.openebs:targetip=10.108.4.158 cstor-2292c294-c6a1-11e9-be30-42010a800094/pvc-5c52d001-c6a1-11e9-be30-42010a800094
Step 12: Edit ‘CStorVolume’ CR of this PVC to increase ReplicationFactor by 1 and to set ConsistencyFactor to (ReplicationFactor/2 + 1)
Step 13: Scale up spec.replicas to 1 of target pod deployment
On performing step 12 and 13, this newly reconstructed replica gets added to the cStor volume.
Status of CStorVolume and CVRs related to this PV looks like:
NAME USED ALLOCATED STATUS AGE
pvc-5c52d001-...........-cstor-sparse-pool-1irk 7.07M 4.12M Offline 3d
pvc-5c52d001-...........-cstor-sparse-pool-a1ud 90.8M 85.0M Healthy 3d
pvc-5c52d001-...........-cstor-sparse-pool-sb1v 90.8M 85.0M Healthy 3d
Check the details of the corresponding cStor volume using the following command:
kubectl get cstorvolume <cStor_volume_name> -n openebs -o yaml
The following is a snippet of the output of the above command:
apiVersion: v1
items:
- apiVersion: openebs.io/v1alpha1
kind: CStorVolume
metadata:
…….
name: pvc-5c52d001-c6a1-11e9-be30-42010a800094
uid: 5c767ae5-c6a1-11e9-be30-42010a800094
spec:
…….
consistencyFactor: 2
iqn: iqn.2016-09.com.openebs.cstor:pvc-5c52d001-c6a1-11e9-be30-42010a800094
replicationFactor: 2
targetPortal: 10.108.4.158:3260
status:
…….
phase: **Healthy**
replicaStatuses:
- checkpointedIOSeq: "1049425"
…….
mode: **Healthy**
quorum: **"1"**
replicaId: "10135959964398189975"
- checkpointedIOSeq: "1049282"
…….
mode: **Healthy**
quorum: **"1"**
replicaId: "3920180363968537568"
Step 14: Scale up spec.replicas of client application.
Step 15: To make third replica healthy, edit ‘CStorVolume’ CR of this PVC to increase ReplicationFactor by 1 and to set ConsistencyFactor to (ReplicationFactor/2 + 1). After doing this change, ReplicationFactor will be 3 and ConsistencyFactor to 2.
Step 16: Restart the cStor target pod deployment of the volume using the following command:
kubectl delete pod <cStor_target_pod> -n openebs
Step 17: After sometime, the third replica will come to healthy state. Status of CVRs related to this PV will looks like below:
NAME USED ALLOCATED STATUS AGE
pvc-5c52d001-...........-cstor-sparse-pool-1irk 90.8M 85.0M Healthy 3d
pvc-5c52d001-...........-cstor-sparse-pool-a1ud 90.8M 85.0M Healthy 3d
pvc-5c52d001-...........-cstor-sparse-pool-sb1v 90.8M 85.0M Healthy 3d
How to verify whether cStor volume is running fine?
Overview
The following items will be discussed:
- Verification of cStor Storage Pool(CSP)
- Verification of cStor Volume
- Verification of cStor Volume Replica(CVR)
Verification of cStor Storage Pool
cStor Storage Pool(CSP) resources are cluster scoped. Status of CSPs can be obtained using the following way.
kubectl get csp
Example output:
NAME ALLOCATED FREE CAPACITY STATUS TYPE AGE
cstor-disk-pool-g5go 270K 9.94G 9.94G Healthy striped 2m
cstor-disk-pool-srj3 270K 9.94G 9.94G Healthy striped 2m
cstor-disk-pool-tla4 270K 9.94G 9.94G Healthy striped 2m
Status of each cStor pool can be found under STATUS column. The following are the different type of STATUS information of cStor pools and their meaning.
Healthy: This state represents cStor pool is online and running.
Offline: cStor pool status is offline due to the following cases:
- when pool creation or pool import is failed.
- when a disk is unavailable in case of the pool is created in a striped manner.
- when tampering happens on CSP resource and invalid values are set then CSP will be updated to offline.
Degraded: cStor pool status is degraded due to the following cases:
- when any one of the disks is unavailable on the node where the pool is created either Mirror, Raidz or Raidz2 manner.
Error: This means cstor-pool container in cStor pool pod is not in running state.
DeletionFailed: There could be an internal error occurred when CSP is deleted.
Note: Status of CSPs are updated only if its corresponding cStor pool pod is Running. If the cStor pool pod of corresponding cStor pool is not running, then the status of cStor pool shown in the above output may be stale.
Verification of cStor Volume
cStor Volume is namespace scoped resource. You have to provide the same namespace where openebs is installed. Status of cStor Volume can be obtained using the following way.
kubectl get cstorvolume -n <openebs_installed_namespace>
Example command:
kubectl get cstorvolume -n openebs
Example output:
NAME STATUS AGE CAPACITY
pvc-4c3baced-c020-11e9-ad45-42010a8001c8 Healthy 1h 5G
Status of each cStor volume can be found under STATUS field.
Note: If the target pod of corresponding cStor volume is not running, then the status of cStor volume shown in the above output may be stale.
The following are the different type of STATUS information of cStor volumes and their definition.
Init: Init status of cStor volume is due to the following cases:
- when the cStor volume is created.
- when the replicas are not connected to target pod.
Healthy: Healthy status of cStor volume represents that 51% of healthy replicas are connected to the target and volume is ready IO operations.
Degraded: Minimum 51% of replicas are connected and some of these replicas are in degraded state, then volume will be running as degraded state and IOs are operational in this state.
Offline: When number of replicas which is equal to Consistency Factor are not yet connected to the target due to network issues or some other reasons In this case, volume is not ready to perform IOs.
For getting the number of replicas connected to the target pod of the cStor volume, use following command:
kubectl get cstorvolume <volume_name> -n <openebs_installed_namespace> -o yaml.
Example output:
In this case, replicationFactor is 3.
status:
capacity: 5G
lastTransitionTime: "2019-08-16T12:22:21Z"
lastUpdateTime: "2019-08-16T13:36:51Z"
phase: Healthy
replicaStatuses:
- checkpointedIOSeq: "0"
inflightRead: "0"
inflightSync: "0"
inflightWrite: "0"
mode: Healthy
quorum: "1"
replicaId: "15881113332075879720"
upTime: 4516
- checkpointedIOSeq: "0"
inflightRead: "0"
inflightSync: "0"
inflightWrite: "0"
mode: Healthy
quorum: "1"
replicaId: "1928348327271356191"
upTime: 4515
- checkpointedIOSeq: "0"
inflightRead: "0"
inflightSync: "0"
inflightWrite: "0"
mode: Healthy
quorum: "1"
replicaId: "3816436440075944405"
upTime: 4514
In the above output, if quorum: **0** then data written to that replica is lost(not ready to read). If quorum: **1** then that replica is ready for Read and Write operation.
If anything went wrong then the error can be seen in cStor volume events kubectl describe cstorvolume <volume_name> -n <openebs_installed_namespace>
Verification of cStor Volume Replica
cStor Volume Replica is namespace scoped resource. You have to provide the same namespace where OpenEBS is installed. Status of cStor Volume Replica can be obtained using the following way.
kubectl get cvr -n <openebs_installed_namespace>
Example command:
kubectl get cvr -n openebs
Example output:
NAME USED ALLOCATED STATUS AGE
pvc-4c3baced-c020-11e9-ad45-42010a8001c8-cstor-disk-pool-g5go 6K 6K Offline 21s
pvc-4c3baced-c020-11e9-ad45-42010a8001c8-cstor-disk-pool-srj3 6K 6K Offline 21s
pvc-4c3baced-c020-11e9-ad45-42010a8001c8-cstor-disk-pool-tla4 6K 6K Offline 21s
Status of each cStor volume Replica can be found under STATUS field.
Note: If the pool pod of corresponding cStor volume replica is not running, then the status of CVR shown in the output of the above command may be stale.
The following are the different type of STATUS information of cStor Volumes Replica and their definition.
Healthy: Healthy state represents volume is healthy and volume data existing on this replica is up to date.
Offline: cStor volume replica status is offline due to the following cases:
- when the corresponding cStor pool is not available to create volume.
- when the creation of cStor volume fails.
- when the replica is not yet connected to the target.
Degraded: cStor volume replica status is degraded due to the following case
- when the cStor volume replica is connected to the target and rebuilding is not yet started on this replica.
Rebuilding: cStor volume replica status is rebuilding when the cStor volume replica is undergoing rebuilding, that means, data sync with another replica.
Error: cStor volume replica status is in error state due to the following cases:
- when the volume replica data set is not existing in the pool.
- when an error occurs while getting the stats of cStor volume.
- when the unit of size is not mentioned in PVC spec. For example, if the size is 5 instead of 5G.
DeletionFailed: cStor volume replica status will be in deletion failed when destroying corresponding cStor volume fails.
Invalid: cStor volume replica status is invalid when a new cstor-pool-mgmt container in a new pod is communicating with the old cstor-pool container in an old pod.
Init: cStor volume replica status init represents the volume is not yet created.
Recreate: cStor volume replica status recreate represents an intermediate state before importing the volume(this can happen only when pool pod got restarted) in case of a non-ephemeral disk. If the disk is ephemeral then this status represents volume is going to recreate.
NewReplicaDegraded: cStor volume replica is newly created and it make successful connection with the target pod.
ReconstructingNewReplica: cStor volume replica is newly created and it started reconstructing entire data from another healthy replica.
Note: If cStor Volume Replica STATUS is in NewReplicaDegraded or NewReplicaReconstructing, then the corresponding volume replica will not be part of the quorum decisions.
Expanding Jiva Storage Volumes
You can resize/expand the OpenEBS volume using the following procedure. Execute the commands from step 2 to 8 as root user on the node where application pod is running.
Step 1: Identify the node where application pod is running. Also note down the IP address of corresponding Jiva controller pod. This IP address is needed in step 7. The above details can be obtained by running the following command:
kubectl get pod -n <namespace> -o wide
Example:
kubectl get pod -n default -o wide
Example output:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
percona-66db7d9b88-ltdsf 1/1 Running 0 9m47s 10.16.0.8 gke-ranjith-jiva-resize-default-pool-ec5045bf-mzf4 <none> <none>
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-ctrl-798dcd69d8-k5v29 2/2 Running 0 9m46s 10.16.1.8 gke-ranjith-jiva-resize-default-pool-ec5045bf-rq1b <none> <none>
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-5fwxr 1/1 Running 0 9m41s 10.16.1.9 gke-ranjith-jiva-resize-default-pool-ec5045bf-rq1b <none> <none>
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-8rclm 1/1 Running 0 9m41s 10.16.0.7 gke-ranjith-jiva-resize-default-pool-ec5045bf-mzf4 <none> <none>
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-sjvtq 1/1 Running 0 9m41s 10.16.2.10 gke-ranjith-jiva-resize-default-pool-ec5045bf-24f1 <none> <none>
In the above sample output, application pod is running on node gke-ranjith-jiva-resize-default-pool-ec5045bf-mzf4 and Jiva controller pod IP is 10.16.1.8.
Step 2: SSH to the node where application pod is running and run the following command.
lsblk
Example output:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 40G 0 disk
├─sda1 8:1 0 39.9G 0 part /
├─sda14 8:14 0 4M 0 part
└─sda15 8:15 0 106M 0 part /boot/efi
sdb 8:16 0 5G 0 disk /home/kubernetes/containerized_mounter/rootfs/var/lib/kubelet/pods/25abb7fa-eb2d-11e9-b8d1-42010a800093/volumes/kubernetes.io~iscsi/pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093
In the above sample output, sdb is the target volume with 5G capacity. Similarly, find out the volume which needs to be resized.
Step 3: Obtain the iSCSI target and disk details using the following command.
iscsiadm -m session -P 3
Example output:
iSCSI Transport Class version 2.0-870
version 2.0-874
Target: iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093 (non-flash)
Current Portal: 10.20.23.99:3260,1
Persistent Portal: 10.20.23.99:3260,1
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.1993-08.org.debian:01:f6771fccb5af
Iface IPaddress: 10.128.0.103
Iface HWaddress: <empty>
Iface Netdev: <empty>
SID: 1
iSCSI Connection State: Unknown
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: Unknown
*********
Timeouts:
*********
Recovery Timeout: 120
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 65536
FirstBurstLength: 65536
MaxBurstLength: 262144
ImmediateData: Yes
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 1 State: running
scsi1 Channel 00 Id 0 Lun: 0
Attached scsi disk sdb State: running
In the above sample output, there is only one volume present on the node. So it is easy to get the iSCSI target IP address and the disk details. In this example disk is sdb, iSCSI target IP is 10.20.23.99:3260, and target iqn is iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093. Similarly, find out the target IP address, IQN and the disk name of the volume that has to be resized and note down these information for future use. If there are many volumes attached on the node, then identify the disk using the PV name.
Step 4 Check the mount path on disk sdb using the following command.
mount | grep /dev/sdb | more
Example snippet of Output:
/dev/sdb on /var/lib/kubelet/plugins/kubernetes.io/iscsi/iface-default/10.20.23.99:3260-iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-lun-0 type ext4 (rw,relatime,data=ordered)
/dev/sdb on /var/lib/kubelet/plugins/kubernetes.io/iscsi/iface-default/10.20.23.99:3260-iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-lun-0 type ext4 (rw,relatime,data=ordered)
/dev/sdb on /home/kubernetes/containerized_mounter/rootfs/var/lib/kubelet/plugins/kubernetes.io/iscsi/iface-default/10.20.23.99:3260-iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-lun-0 type ext4 (rw,relatime,data=ordered)
/dev/sdb on /home/kubernetes/containerized_mounter/rootfs/var/lib/kubelet/plugins/kubernetes.io/iscsi/iface-default/10.20.23.99:3260-iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-lun-0 type ext4 (rw,relatime,data=ordered)
/dev/sdb on /var/lib/kubelet/pods/25abb7fa-eb2d-11e9-b8d1-42010a800093/volumes/kubernetes.io~iscsi/pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093 type ext4 (rw,relatime,data=ordered)
/dev/sdb on /var/lib/kubelet/pods/25abb7fa-eb2d-11e9-b8d1-42010a800093/volumes/kubernetes.io~iscsi/pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093 type ext4 (rw,relatime,data=ordered)
/dev/sdb on /home/kubernetes/containerized_mounter/rootfs/var/lib/kubelet/pods/25abb7fa-eb2d-11e9-b8d1-42010a800093/volumes/kubernetes.io~iscsi/pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093 type ext4 (rw,relatime,data=ordered)
/dev/sdb on /home/kubernetes/containerized_mounter/rootfs/var/lib/kubelet/pods/25abb7fa-eb2d-11e9-b8d1-42010a800093/volumes/kubernetes.io~iscsi/pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093 type ext4 (rw,relatime,data=ordered)
Step 5: Unmount the file system using following command. The following is an example command with respect to the above output. Update correct mount path according to your deployment. Ensure that you are running following commands as super user.
umount /var/lib/kubelet/plugins/kubernetes.io/iscsi/iface-default/10.20.23.99:3260-iqn.2016-09.co
m.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-lun-0
umount /var/lib/kubelet/pods/25abb7fa-eb2d-11e9-b8d1-42010a800093/volumes/kubernetes.io~iscsi/pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093
Step 6: Logout from the particular iSCSI target using the following command:
iscsiadm -m node -u -T <target_iqn>
Example:
iscsiadm -m node -u -T iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093
Example output:
Logging out of session [sid: 1, target: iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093, portal: 10.20.23.99,3260]
Logout of [sid: 1, target: iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093, portal: 10.20.23.99,3260] successful
Step 7: Get the volume ID using the following command:
curl http://<Jiva_controller_pod_ip>:9501/v1/volumes
Example:
curl http://10.16.1.8:9501/v1/volumes
Example output:
{"data":[{"actions":{"deleteSnapshot":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==?action=deleteSnapshot","revert":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==?action=revert","shutdown":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==?action=shutdown","snapshot":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==?action=snapshot"},"id":"cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==","links":{"self":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw=="},"name":"pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093","readOnly":"false","replicaCount":3,"type":"volume"}],"links":{"self":"http://10.16.1.8:9501/v1/volumes"},"resourceType":"volume","type":"collection"}
From above example output, You can find volume id is cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==, Jiva target pod IP is 10.16.1.8, and the Volume name is pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093. These parameters are required in the next step.
Step 8: Specify desired size of volume and the above parameters in the following command.
curl -H "Content-Type: application/json" -X POST -d '{"name":"pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093","size":"8G"}' http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==?action=resize
Example output:
{"actions":{"deleteSnapshot":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==?action=deleteSnapshot","revert":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==?action=revert","shutdown":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==?action=shutdown","snapshot":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==?action=snapshot"},"id":"cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw==","links":{"self":"http://10.16.1.8:9501/v1/volumes/cHZjLTI1ZThmNmYxLWViMmQtMTFlOS1iOGQxLTQyMDEwYTgwMDA5Mw=="},"name":"pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093","readOnly":"false","replicaCount":3,"type":"volume"}
From the above output, volume has been expanded to 8G.
Step 9: Run step 9 and step 10 from Kubernetes master node. Get the Jiva pod details using the following command:
kubectl get pods -n <application_namespace>
Example output:
NAME READY STATUS RESTARTS AGE
percona-66db7d9b88-ltdsf 1/1 Running 0 6h38m
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-ctrl-798dcd69d8-k5v29 2/2 Running 0 6h38m
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-5fwxr 1/1 Running 0 6h38m
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-8rclm 1/1 Running 0 6h38m
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-sjvtq 1/1 Running 0 6h38m
Step 10: Restart all replica pods of the corresponding volume using the following command. If the replica count of Jiva volume is more than 1, then you must delete all the replica pods of corresponding Jiva volume simultaneously using single command.
kubectl delete pods <replica_pod_1> <replica_pod_2> ... <replica_pod_n> -n <application_namespace>
Example:
kubectl delete pod pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-5fwxr pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-8rclm pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-sjvtq -n default
Example output:
pod "pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-5fwxr" deleted
pod "pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-8rclm" deleted
pod "pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-sjvtq" deleted
Verify if new Jiva pods are running successfully using:
kubectl get pods -n <application_namespace>
Step 11: Perform step 11 to 15 as root user on node where the application pod is running. Perform iSCSI target login using the following commands.
iscsiadm -m discovery -t st -p <Jiva_controller_ip>:3260
Example:
iscsiadm -m discovery -t st -p 10.16.1.8:3260
Example output:
10.20.23.99:3260,1 iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093
From above output, iSCSI target IP is 10.20.23.99:3260.
Now, Login to the iSCSI target using the following command:
iscsiadm -m discovery -t st -p 10.20.23.99:3260 -l
Example output:
10.20.23.99:3260,1 iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093
Logging in to [iface: default, target: iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093, portal: 10.20.23.99,3260] (multiple)
Login to [iface: default, target: iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093, portal: 10.20.23.99,3260] successful.
Step 12: Verify the resized disk details using the following command:
lsblk
Example output:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 40G 0 disk
├─sda1 8:1 0 39.9G 0 part /
├─sda14 8:14 0 4M 0 part
└─sda15 8:15 0 106M 0 part /boot/efi
sdc 8:32 0 8G 0 disk
From the above output, You can see the resized disk is sdc with 8G capacity.
Step 13: Check the file system consistency using the following command:
e2fsck -f <expanded_device_path>
In following example, /dev/sdc is the newly expanded disk.
e2fsck -f /dev/sdc
Example output:
e2fsck 1.44.1 (24-Mar-2018)
/dev/sdc: recovering journal
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
Free blocks count wrong (1268642, counted=1213915).
Fix<y>? yes
Free inodes count wrong (327669, counted=327376).
Fix<y>? yes
/dev/sdc: ***** FILE SYSTEM WAS MODIFIED *****
/dev/sdc: 304/327680 files (7.2% non-contiguous), 96805/1310720 blocks
Step 14: Expand the file system using the following command. In the following example, /dev/sdc is the newly expanded disk.
resize2fs /dev/sdc
Example output:
resize2fs 1.44.1 (24-Mar-2018)
Resizing the filesystem on /dev/sdc to 2097152 (4k) blocks.
The filesystem on /dev/sdc is now 2097152 (4k) blocks long.
Step 15: Mount the file system using the following commands as root user:
mount /dev/sdc /var/lib/kubelet/plugins/kubernetes.io/iscsi/iface-default/10.20.23.99:3260-iqn.2016-09.com.openebs.jiva:pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-lun-0
mount /dev/sdc /var/lib/kubelet/pods/25abb7fa-eb2d-11e9-b8d1-42010a800093/volumes/kubernetes.io~iscsi/pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093
Step 16: Execute the below command in Kubernetes master node. Restart the application pod using the following command:
kubectl delete pod <application_pod>
Verify if the application pod is running using the following command. Note down the node where the application pod is running now.
kubectl get pod -n <application_namespace> -o wide
Example output:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
percona-66db7d9b88-bnr8w 1/1 Running 0 81m 10.16.2.12 gke-ranjith-jiva-resize-default-pool-ec5045bf-24f1 <none> <none>
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-ctrl-798dcd69d8-k5v29 2/2 Running 0 8h 10.16.1.8 gke-ranjith-jiva-resize-default-pool-ec5045bf-rq1b <none> <none>
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-65c8z 1/1 Running 0 94m 10.16.1.10 gke-ranjith-jiva-resize-default-pool-ec5045bf-rq1b <none> <none>
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-6znbr 1/1 Running 1 94m 10.16.0.9 gke-ranjith-jiva-resize-default-pool-ec5045bf-mzf4 <none> <none>
pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093-rep-56866d8696-m9lrx 1/1 Running 0 94m 10.16.2.11 gke-ranjith-jiva-resize-default-pool-ec5045bf-24f1 <none> <none>
Step 17: Identify the node where new application pod is running. Then SSH to the node to verify the expanded size and execute the following command:
lsblk
Example output:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 40G 0 disk
├─sda1 8:1 0 39.9G 0 part /
├─sda14 8:14 0 4M 0 part
└─sda15 8:15 0 106M 0 part /boot/efi
sdb 8:16 0 8G 0 disk /home/kubernetes/containerized_mounter/rootfs/var/lib/kubelet/pods/164201d0-ebcc-11e9-b8d1-42010a800093/volumes/kubernetes.io~iscsi/pvc-25e8f6f1-eb2d-11e9-b8d1-42010a800093
Step 18: Verify the expanded size from application pod.
Note: After the volume expansion, size will not be reflected on kubectl get pv for the corresponding volume.